HBase是Hadoop的数据库,能够对大数据提供随机、实时读写访问。他是开源的,分布式的,多版本的,面向列的,存储模型。
在讲解的时候我首先给大家讲解一下HBase的整体结构,如下图:
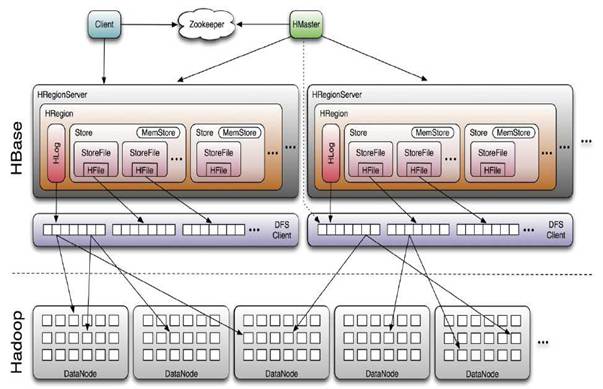
HBase Master是服务器负责管理所有的HRegion服务器,HBase Master并不存储HBase服务器的任何数据,HBase逻辑上的表可能会划分为多个HRegion,然后存储在HRegion Server群中,HBase Master Server中存储的是从数据到HRegion Server的映射。
一台机器只能运行一个HRegion服务器,数据的操作会记录在Hlog中,在读取数据时候,HRegion会先访问Hmemcache缓存,如果 缓存中没有数据才回到Hstore中上找,没一个列都会有一个Hstore集合,每个Hstore集合包含了很多具体的HstoreFile文件,这些文 件是B树结构的,方便快速读取。
再看下HBase数据物理视图如下:
|
Row Key
|
Timestamp
|
Column Family
|
|
URI
|
Parser
|
|
r1 |
t3 |
url=http://www.taobao.com |
title=天天特价 |
|
t2 |
host=taobao.com |
|
|
t1 |
|
|
|
r2 |
t5 |
url=http://www.alibaba.com |
content=每天… |
|
t4 |
host=alibaba.com |
|
Ø<wbr>Row Key: 行键,Table的主键,Table中的记录按照Row Key排序</wbr>
Ø<wbr>Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number</wbr>
Ø<wbr>Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。</wbr>
了解了HBase的体系结构和HBase数据视图够,现在让我们一起看看怎样通过Java来操作HBase数据吧!
先说说具体的API先,如下
HBaseConfiguration是每一个hbase client都会使用到的对象,它代表的是HBase配置信息。它有两种构造方式:
public HBaseConfiguration()
public HBaseConfiguration(final Configuration c)
默认的构造方式会尝试从hbase-default.xml和hbase-site.xml中读取配置。如果classpath没有这两个文件,就需要你自己设置配置。
Configuration HBASE_CONFIG = new Configuration();
HBASE_CONFIG.set(“hbase.zookeeper.quorum”, “zkServer”);
HBASE_CONFIG.set(“hbase.zookeeper.property.clientPort”, “2181″);
HBaseConfiguration cfg = new HBaseConfiguration(HBASE_CONFIG);
创建表
创建表是通过HBaseAdmin对象来操作的。HBaseAdmin负责表的META信息处理。HBaseAdmin提供了createTable这个方法:
public void createTable(HTableDescriptor desc)
HTableDescriptor 代表的是表的schema, 提供的方法中比较有用的有
setMaxFileSize,指定最大的region size
setMemStoreFlushSize 指定memstore flush到HDFS上的文件大小
增加family通过 addFamily方法
public void addFamily(final HColumnDescriptor family)
HColumnDescriptor 代表的是column的schema,提供的方法比较常用的有
setTimeToLive:指定最大的TTL,单位是ms,过期数据会被自动删除。
setInMemory:指定是否放在内存中,对小表有用,可用于提高效率。默认关闭
setBloomFilter:指定是否使用BloomFilter,可提高随机查询效率。默认关闭
setCompressionType:设定数据压缩类型。默认无压缩。
setMaxVersions:指定数据最大保存的版本个数。默认为3。
一个简单的例子,创建了4个family的表:
HBaseAdmin hAdmin = new HBaseAdmin(hbaseConfig);
HTableDescriptor t = new HTableDescriptor(tableName);
t.addFamily(new HColumnDescriptor(“f1″));
t.addFamily(new HColumnDescriptor(“f2″));
t.addFamily(new HColumnDescriptor(“f3″));
t.addFamily(new HColumnDescriptor(“f4″));
hAdmin.createTable(t);
删除表
删除表也是通过HBaseAdmin来操作,删除表之前首先要disable表。这是一个非常耗时的操作,所以不建议频繁删除表。
disableTable和deleteTable分别用来disable和delete表。
Example:
HBaseAdmin hAdmin = new HBaseAdmin(hbaseConfig);
if (hAdmin.tableExists(tableName)) {
hAdmin.disableTable(tableName);
hAdmin.deleteTable(tableName);
}
查询数据
查询分为单条随机查询和批量查询。
单条查询是通过rowkey在table中查询某一行的数据。HTable提供了get方法来完成单条查询。
批量查询是通过制定一段rowkey的范围来查询。HTable提供了个getScanner方法来完成批量查询。
public Result get(final Get get)
public ResultScanner getScanner(final Scan scan)
Get对象包含了一个Get查询需要的信息。它的构造方法有两种:
public Get(byte [] row)
public Get(byte [] row, RowLock rowLock)
Rowlock是为了保证读写的原子性,你可以传递一个已经存在Rowlock,否则HBase会自动生成一个新的rowlock。
Scan对象提供了默认构造函数,一般使用默认构造函数。
Get/Scan的常用方法有:
addFamily/addColumn:指定需要的family或者column,如果没有调用任何addFamily或者Column,会返回所有的columns.
setMaxVersions:指定最大的版本个数。如果不带任何参数调用setMaxVersions,表示取所有的版本。如果不掉用setMaxVersions,只会取到最新的版本。
setTimeRange:指定最大的时间戳和最小的时间戳,只有在此范围内的cell才能被获取。
setTimeStamp:指定时间戳。
setFilter:指定Filter来过滤掉不需要的信息
Scan特有的方法:
setStartRow:指定开始的行。如果不调用,则从表头开始。
setStopRow:指定结束的行(不含此行)。
setBatch:指定最多返回的Cell数目。用于防止一行中有过多的数据,导致OutofMemory错误。
ResultScanner是Result的一个容器,每次调用ResultScanner的next方法,会返回Result.
public Result next() throws IOException;
public Result [] next(int nbRows) throws IOException;
Result代表是一行的数据。常用方法有:
getRow:返回rowkey
raw:返回所有的key value数组。
getValue:按照column来获取cell的值
Example:
Scan s = new Scan();
s.setMaxVersions();
ResultScanner ss = table.getScanner(s);
for(Result r:ss){
System.out.println(new String(r.getRow()));
for(KeyValue kv:r.raw()){
System.out.println(new String(kv.getColumn()));
}
}
插入数据
HTable通过put方法来插入数据。
public void put(final Put put) throws IOException
public void put(final List puts) throws IOException
可以传递单个批Put对象或者List put对象来分别实现单条插入和批量插入。
Put提供了3种构造方式:
public Put(byte [] row)
public Put(byte [] row, RowLock rowLock)
public Put(Put putToCopy)
Put常用的方法有:
add:增加一个Cell
setTimeStamp:指定所有cell默认的timestamp,如果一个Cell没有指定timestamp,就会用到这个值。如果没有调用,HBase会将当前时间作为未指定timestamp的cell的timestamp.
setWriteToWAL: WAL是Write Ahead Log的缩写,指的是HBase在插入操作前是否写Log。默认是打开,关掉会提高性能,但是如果系统出现故障(负责插入的Region Server挂掉),数据可能会丢失。
另外HTable也有两个方法也会影响插入的性能
setAutoFlash: AutoFlush指的是在每次调用HBase的Put操作,是否提交到HBase Server。默认是true,每次会提交。如果此时是单条插入,就会有更多的IO,从而降低性能.
setWriteBufferSize: Write Buffer Size在AutoFlush为false的时候起作用,默认是2MB,也就是当插入数据超过2MB,就会自动提交到Server
Example:
HTable table = new HTable(hbaseConfig, tableName);
table.setAutoFlush(autoFlush);
List lp = new ArrayList();
int count = 10000;
byte[] buffer = new byte[1024];
Random r = new Random();
for (int i = 1; i <= count; ++i) {
Put p = new Put(String.format(“row%09d”,i).getBytes());
r.nextBytes(buffer);
p.add(“f1″.getBytes(), null, buffer);
p.add(“f2″.getBytes(), null, buffer);
p.add(“f3″.getBytes(), null, buffer);
p.add(“f4″.getBytes(), null, buffer);
p.setWriteToWAL(wal);
lp.add(p);
if(i%1000==0){
table.put(lp);
lp.clear();
}
}
删除数据
HTable 通过delete方法来删除数据。
public void delete(final Delete delete)
Delete构造方法有:
public Delete(byte [] row)
public Delete(byte [] row, long timestamp, RowLock rowLock)
public Delete(final Delete d)
Delete常用方法有
deleteFamily/deleteColumns:指定要删除的family或者column的数据。如果不调用任何这样的方法,将会删除整行。
注意:如果某个Cell的timestamp高于当前时间,这个Cell将不会被删除,仍然可以查出来。
Example:
HTable table = new HTable(hbaseConfig, “mytest”);
Delete d = new Delete(“row1″.getBytes());
table.delete(d)
切分表
HBaseAdmin提供split方法来将table 进行split.
public void split(final String tableNameOrRegionName)
如果提供的tableName,那么会将table所有region进行split ;如果提供的region Name,那么只会split这个region.
由于split是一个异步操作,我们并不能确切的控制region的个数。
Example:
public void split(String tableName,int number,int timeout) throws Exception {
Configuration HBASE_CONFIG = new Configuration();
HBASE_CONFIG.set(“hbase.zookeeper.quorum”, GlobalConf.ZOOKEEPER_QUORUM);
HBASE_CONFIG.set(“hbase.zookeeper.property.clientPort”, GlobalConf.ZOOKEEPER_PORT);
HBaseConfiguration cfg = new HBaseConfiguration(HBASE_CONFIG);
HBaseAdmin hAdmin = new HBaseAdmin(cfg);
HTable hTable = new HTable(cfg,tableName);
int oldsize = 0;
t = System.currentTimeMillis();
while(true){
int size = hTable.getRegionsInfo().size();
logger.info(“the region number=”+size);
if(size>=number ) break;
if(size!=oldsize){
hAdmin.split(hTable.getTableName());
oldsize = size;
} else if(System.currentTimeMillis()-t>timeout){
break;
}
Thread.sleep(1000*10);
}
}




相关推荐
Hbase Java API详解 是开发hbase 数据库很好的收 对初学者有好友
第二部分,对Hbase进行基本的概述,主要介绍其中基本原理,第三部分对Hbase的技术进行详解,包括关键成员和技术优化。第四部分,通过一个小的java api案例,介绍Hbase的开发使用,详细分析hbase的应用场景和优化方式...
HBase对于非Java语言提供了Thrift接口支持,这里结合对HBase Thrift接口(HBase版本为0.92.1)的使用经验,总结其中遇到的一些问题及其相关注意事项。1. 字节的存放顺序HBase中,由于row(row key和column family、...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
前 言 大数据学习路线 大数据技术栈思维导图 大数据常用软件安装指南 ...六、HBase 简介 系统架构及数据结构 基本环境搭建 集群环境搭建 常用 Shell 命令 Java API 过滤器详解 可显示字数有限,详细内容请看资源。
HDFS Java API 的使用 基于 Zookeeper 搭建 Hadoop 高可用集群 Hive Hive 简介及核心概念 Linux 环境下 Hive 的安装部署 Hive CLI 和 Beeline 命令行的基本使用 Hive 常用 DDL 操作 Hive 分区表和分桶表 Hive 视图...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...
07.Kafka Java API 简单开发测试 08.storm-kafka 详解和实战案例 09.S图表框架HighCharts介绍 10.HBase快速入门 11.基于HBase的Dao基类和实现类开发一 12.基于HBase的Dao基类和实现类开发二 13.项目1-地区销售额-...